全栈工程师指南




架构模式,都在不断地降低技术的门槛。而这些门槛的降低,已经足以让一两个人来完成大部分的工作了。
PHP 新手也是这样写代码的。
好了,这时候我们就可以讨论讨论 MVC 模式了。
敏捷是为了解决组织内沟通的问题,从敏捷到精益不仅仅优化了组织内的沟通问题,还强化了与外部的关系。换句话说,精益结合了一部分的互联网思维。
测试的、没有 Code Review 等等。当然,这也不是一篇关于如何实践敏捷的文章。敏捷与瀑布式开发在很大的区别就是:沟通问题。传统的软件开发在调研完毕后就是分析、开发等等。而敏捷开发则会强调这个过程中的沟通问题:
 敏捷软件开发的沟通模型
敏捷软件开发的沟通模型
敏捷软件开发的沟通模型
在整个过程中都不断地强调沟通问题,然而这时还存在一个问题:组织结构本身的问题。这样的组织结构,如下图所示:
 组织结构
组织结构
如果市场部门/产品经理没有与研发团队坐一起来分析问题,那么问题就多了。当一个需求在实现的过程中遇到问题,到底是哪个部门的问题?
同样的如果我们的研发部门是这样子的结构:
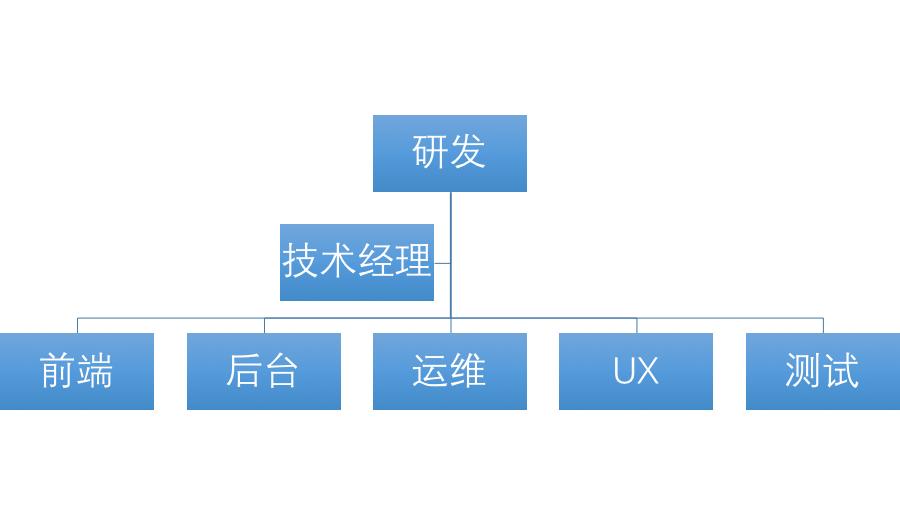 研发部门
研发部门
那么在研发、上线的过程中仍然会遇到各种的沟通问题。
现在,让我们回过头来看看大公司的专家与小公司的全栈。
AngularJS 这样的框架便是例子,前端结合后端开发语言 Java 的思维而产生。而专家则依赖于内部的条件,创造出不一样的适应式创新。如之前流行的 Backbone 框架,适应当时的情况而产生。
JavaScript、Java、Python、Ruby)的问题来问我,我只想说 Ciao —— 意大利语:你好!
除了这个问题——人们不了解什么是全栈工程师。还有一个问题,就是刚才我们说的成为专家的老大难问题。
操作系统、内核、游戏编程 -> 大学: 硬件、Web 开发 -> 工作:后端 + 前端
而在当时我对 SEO 非常感兴趣,我发现这分析和 Marketing 似乎做得还可以。然后便往 Growth Hacking 发展了:
 Growth Hacking
Growth Hacking
而这就是全栈学习带来的优势,学过的东西多,学习能力就变强。学习能力往上提的同时,你就更容易进入一个新的领域。
参考书籍
- 《精益企业: 高效能组织如何规模化创新》
- 《企业应用架构模式》
- 《敏捷软件开发》
- 《技术的本质》
C语言程序设计》也保留了这个范例程式。工作时,我们也会使用类似于 hello,world 的 boilerplate 来完成基本的项目创建。
同时需要注意的一点是,在每个大的项目开始之前我们应该去找寻好开发环境。搭建环境是一件非常重要的事,它决定了你能不能更好地工作。毕竟环境是生产率的一部分。高效的程序员和低效程序员间的十倍差距,至少有三倍是因为环境差异。
因此在这一章里,我们将讲述几件事情:
- 使用怎样的操作系统
- 如何去选择工具
- 如何搭建相应操作系统上的环境
- 如何去学习一门语言
Linux 下面的命令有一大堆,只是我们常用的只有一小部分——20%的命令能够完成80%的工作。如同 CISC 和 RISC 一样,我们所常用的指令会让我们忘却那些不常用的指令。而那些是最实用的,如同我们日常工作中使用的 Linux 一样,记忆过多的不实用的东西,不比把他们记在笔记上实在。我们只需要了解有那些功能,如何去用他。
Node.js 火了。选择工具本身是一件很有趣的事,因为有着越来越多的可能性。
过去 PHP 是主流的开发,不过现在也是,PHP 为 WEB 而生。有一天 Ruby on Rails 出现了,一切就变了,变得高效,变得更 Powerful。MVC 一直很不错,不是么?于是越来越多的框架出现了,如 Django,Laravel 等等。不同的语言有着不同的框架,JavaScript 上也有着合适的框架,如 AngularJS。不同语言的使用者们用着他们合适的工具,因为学习新的东西,对于多数的人来说就是一种新的挑战。在学面向对象语言的时候,人们很容易把程序写成过程式的。
没有合适的工具,要么创造一个,要么选择一个合适的。
嵌入式的时候 IDE 会有效率一点。
以前不知道 WebStorm 的时候,习惯用 DW 来格式化 HTML,Aptana 来格式化 JavaScript。
以前,习惯用 WordPress 来写博客,因为可以有移动客户端,使用电脑时就不喜欢打开浏览器去写。
等等
等
前端开发来说,我们可能使用 Chrome 的 Dev Tools。但是对于后端来说,我们就需要使用别的工具。如下图所示的是 Intellij Idea 的 Debug 界面:
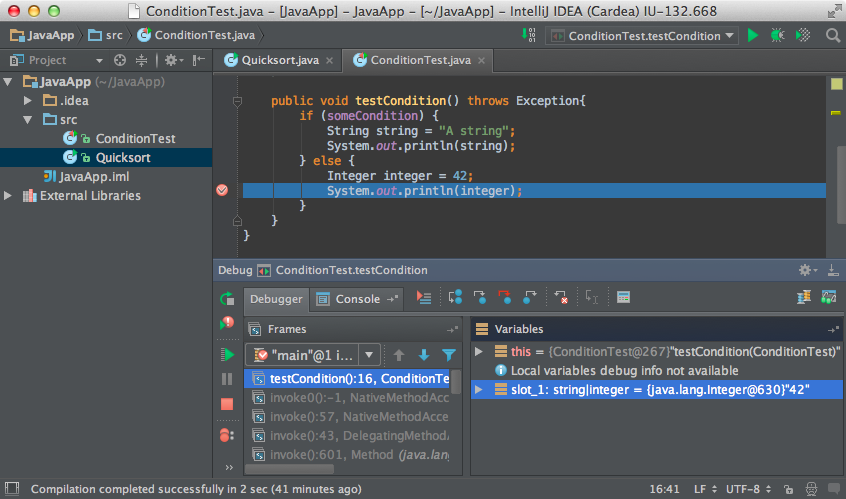 Intellij Idea Debug
Intellij Idea Debug
在 Debug 的过程中,我们可以根据代码的执行流程一步步向下执行。这也意味着,当出现 Bug 的时候我们可以更容易找到 Bug。这就是为什么他叫 Debug 工具的原因了。
数据库之中,以用于软件包检索。
依赖关系 (dependencies) 是软件包管理的一个重要方面。实际上每个软件包都会涉及到其他的软件包,软件包里程序的运行需要有一个可执行的环境(要求有其他的程序、库等),软件包依赖关系正是用来描述这种关系的。
我们经常会使用各式各样的包管理工具,来加速我们地日常使用。而不是 Google 某个软件,然后下载,接着安装。
Homebrew
包管理工具,官方称之为 The missing package manager for OS X。
包管理工具,官方称之为 The missing package manager for OS X。
brew-cask 允许你使用命令行安装 OS X 应用。
iTerm2 是最常用的终端应用,是 Terminal 应用的替代品。
Zsh 是一款功能强大终端(shell)软件,既可以作为一个交互式终端,也可以作为一个脚本解释器。它在兼容 Bash 的同时 (默认不兼容,除非设置成 emulate sh) 还有提供了很多改进,例如:
- 更高效
- 更好的自动补全
- 更好的文件名展开(通配符展开)
- 更好的数组处理
- 可定制性高
Oh My Zsh 同时提供一套插件和工具,可以简化命令行操作。
强大的文件编辑器。
MacDown 是 Markdown 编辑器。
CheatSheet 能够显示当前程序的快捷键列表,默认的快捷键是长按⌘。
SourceTree 是 Atlassian 公司出品的一款优秀的 Git 图形化客户端。
Mac 用户不用鼠标键盘的必备神器,配合大量 Workflows,习惯之后可以大大减少操作时间。
上手简单,调教成本在后期自定义 Workflows,不过有大量雷锋使用者提供的现成扩展,访问这里挑选喜欢的,并可以极其简单地根据自己的需要修改。
Vimium 是一个 Google Chrome 扩展,让你可以纯键盘操作 Chrome。
相关参考:
Chocolatey
Chocolatey 是一个软件包管理工具,类似于 Ubuntu 下面的 apt-get,不过是运行在 Windows 环境下面。
Chocolatey 是一个软件包管理工具,类似于 Ubuntu 下面的 apt-get,不过是运行在 Windows 环境下面。
Wox 是一个高效的快速启动器工具,通过快捷键呼出,然后输入关键字来搜索程序进行快速启动,或者搜索本地硬盘的文件,打开百度、Google 进行搜索,甚至是通过一些插件的功能实现单词翻译、关闭屏幕、查询剪贴板历史、查询编程文档、查询天气等更多功能。它最大的特点是可以支持中文拼音的模糊匹配。
Windows PowerShell 是微软公司为 Windows 环境所开发的壳程序(shell)及脚本语言技术,采用的是命令行界面。这项全新的技术提供了丰富的控制与自动化的系统管理能力。
cmder 把 conemu,msysgit 和 clink 打包在一起,让你无需配置就能使用一个真正干净的 Linux 终端!她甚至还附带了漂亮的 monokai 配色主题。
Total Commander 是一款应用于 Windows 平台的文件管理器 ,它包含两个并排的窗口,这种设计可以让用户方便地对不同位置的“文件或文件夹”进行操作,例如复制、移动、删除、比较等,相对 Windows 资源管理器而言方便很多,极大地提高了文件操作的效率,被广大软件爱好者亲切地简称为:TC 。
Zsh
Zsh 是一款功能强大终端(shell)软件,既可以作为一个交互式终端,也可以作为一个脚本解释器。它在兼容 Bash 的同时 (默认不兼容,除非设置成 emulate sh) 还有提供了很多改进,例如:
- 更高效
- 更好的自动补全
- 更好的文件名展开(通配符展开)
- 更好的数组处理
- 可定制性高
Oh My Zsh 同时提供一套插件和工具,可以简化命令行操作。
ReText 是一个使用 Markdown 语法和 reStructuredText (reST) 结构的文本编辑器,编辑的内容支持导出到 PDF、ODT 和 HTML 以及纯文本,支持即时预览、网页生成以及 HTML 语法高亮、全屏模式,可导出文件到 Google Docs 等。
Launchy 是一款免费开源的协助您摒弃 Windows “运行”的 Dock 式替代工具,既方便又实用,自带多款皮肤,作为美化工具也未尝不可。
环境搭建完毕!现在,就让我们来看看如何学好一门语言!
Scala 语言的初学者,接着我用搜索引擎去搜索『Scala』来看看『Scala』是什么鬼:
Scala 是一门类 Java 的编程语言,它结合了面向对象编程和函数式编程。
Scala 是一门类 Java 的编程语言,它结合了面向对象编程和函数式编程。
接着又开始看『Scala ‘hello,world’』,然后找到了这样的一个示例:
object HelloWorld {
def main(args: Array[String]): Unit = {
println("Hello, world!")
}
}GET 到了5%的知识。
看上去这门语言相比于 Java 语言来说还行。然后我找到了一本名为『Scala 指南』的电子书,有这样的一本目录:
- 表达式和值
- 函数是一等公民
- 借贷模式
- 按名称传递参数
- 定义类
- 鸭子类型
- 柯里化
- 范型
- Traits
- …
看上去还行, 又 GET 到了5%的知识点。接着,依照上面的代码和搭建指南在自己的电脑上安装了 Scala 的环境:
brew install scalaWindows 用户可以用:
choco install scala然后开始写一个又一个的 Demo,感觉自己 GET 到了很多特别的知识点。
到了第二天忘了!
 Bro Wrong
Bro Wrong
接着,你又重新把昨天的知识过了一遍,还是没有多大的作用。突然间,你听到别人在讨论什么是这个世界上最好的语言——你开始加入讨论了。
于是,你说出了 Scala 这门语言可以:
- 支持高阶函数。lambda,闭包…
- 支持偏函数。 match..
- mixin,依赖注入..
- 等等
虽然隔壁的 Python 小哥赢得了这次辩论,然而你发现你又回想起了 Scala 的很多特性。
 最流行的语言
最流行的语言
你发现隔壁的 Python 小哥之所以赢得了这场辩论是因为他把 Python 语言用到了各个地方——机器学习、人工智能、硬件、Web开发、移动应用等。而你还没有用 Scala 写过一个真正的应用。
让我想想我能做什么?我有一个博客。对,我有一个博客,可以用 Scala 把我的博客重写一遍:
- 先找一 Scala 的 Web 框架,Play 看上去很不错,就这个了。这是一个 MVC 框架,原来用的 Express 也是一个 MVC 框架。Router 写这里,Controller 类似这个,就是这样的。
- 既然已经有 PyJS,也会有 Scala-js,前端就用这个了。
好了,博客重写了一遍了。
感觉还挺不错的,我决定向隔壁的 Java 小弟推销这门语言,以解救他于火海之中。
『让我想想我有什么杀手锏?』
『这里的知识好像还缺了一点,这个是什么?』
好了,你已经 GET 到了90%了。如下图所示:
 Learn
Learn
希望你能从这张图上 GET 到很多点。
spring MVC + Bootstrap + jQuery
那么在那个合适的年代里, 我们需要单页面应用,就使用了Backbone。然后,我们就可以用 Mustache + HTML 来替换掉 JSP。
第二个系统(v2): Spring MVC + Backbone + Mustache
在这时我们已经实现了前后端分离了,这时候系统实现上变成了这样。
第二个系统(v2.2): RESTful Services + Backbone + Mustache
或者
第二个系统(v2.2): RESTful Services + AngularJS 1.x
Spring 只是一个 RESTful 服务,我们还需要一些问题,比如 DOM 的渲染速度太慢了。
第三个系统(v3): RESTful Services + React
系统就是这样一步步演进过来的。
尽管在最后系统的架构已经不是当初的架构,而系统本身的业务逻辑变化并没有发生太大的变化。
特别是对于如博客这一类的系统来说,他的一些技术实现已经趋于稳定,而且是你经常使用的东西。所以,下次试试用新的技术的时候,可以先从对你的博客的重写开始。
http://curl.haxx.se/download.html下载到),那么我们可以直接用下面的命令来看这看这个过程(-v 参数可以显示一次 http 通信的整个过程):
curl -v https://www.phodal.com
curl -v https://www.phodal.com我们就会看到下面的响应过程:
* Rebuilt URL to: https://www.phodal.com/
* Trying 54.69.23.11...
* Connected to www.phodal.com (54.69.23.11) port 443 (#0)
* TLS 1.2 connection using TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384
* Server certificate: www.phodal.com
* Server certificate: COMODO RSA Domain Validation Secure Server CA
* Server certificate: COMODO RSA Certification Authority
* Server certificate: AddTrust External CA Root
> GET / HTTP/1.1
> Host: www.phodal.com
> User-Agent: curl/7.43.0
> Accept: */*
>
< HTTP/1.1 403 Forbidden
< Server: phodal/0.19.4
< Date: Tue, 13 Oct 2015 05:32:13 GMT
< Content-Type: text/html; charset=utf-8
< Content-Length: 170
< Connection: keep-alive
<
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>phodal/0.19.4</center>
</body>
</html>
* Connection #0 to host www.phodal.com left intact我们尝试用 cURL 去访问我的网站,会根据访问的域名找出其 IP,通常这个映射关系是来源于 ISP 缓存 DNS(英语:Domain Name System)服务器[^DNSServer]。
以“*”开始的前8行是一些连接相关的信息,称为响应首部。我们向域名 https://www.phodal.com/发出了请求,接着 DNS服务器告诉了我们网站服务器的 IP,即54.69.23.11。出于安全考虑,在这里我们的示例,我们是以 HTTPS 协议为例,所以在这里连接的端口是 443。因为使用的是 HTTPS 协议,所以在这里会试图去获取服务器证书,接着获取到了域名相关的证书信息。
随后以“>”开始的内容,便是向Web服务器发送请求。Host 即是我们要访问的主机的域名,GET / 则代表着我们要访问的是根目录,如果我们要访问 https://www.phodal.com/about/页面在这里,便是 GET 资源文件 /about。紧随其后的是 HTTP 的版本号(HTTP/1.1)。User-Agent 通常指向的是使用者行为的软件,通常会加上硬件平台、系统软件、应用软件和用户个人偏好等等的一些信息。Accept 则指的是告知服务器发送何种媒体类型。
这个过程,大致如下图所示:
 DNS 到服务器的过程
DNS 到服务器的过程
在图中,我们会发现解析 DNS 的时候,我们需要先本地 DNS 服务器查询。如果没有的话,再向根域名服务器查询——这个域名由哪个服务器来解析。直至最后拿到真正的服务器IP才能获取页面。
当我们拿到相应的 HTML、JS、CSS 后,我们就开始渲染这个页面了。
How browsers work》
CSS3 做出更多有趣的效果,而这些并不在我们的讨论范围里面,因为我们讨论的是 be a geek。
或许我们写的代码都是那么的简单,从 HTML 到 JavaScript,还有现在的 CSS,只是总有一些核心的东西,而不是去考虑那些基础语法,基础的东西我们可以在实践的过程中一一发现。但是我们可能发现不了,或者在平时的使用中考虑不到一些有趣的用法或者说特殊的用法,这时候可以通过观察一些精致设计的代码中学习到。复杂的东西可以变得很简单,简单的东西也可以变得很复杂。
Oracle 不毁坏 Java,那么他会继续存活很久。我可以用 JavaScript 造出各种我想要的东西,但是通常我无法保证他们是优雅的实现。过去人们在 Java 上花费了很多的时间,或在架构上,或在语言上,或在模式上。由于这些投入,都给了人们很多的启发。这些都可以用于新的语言,新的设计,毕竟没有什么技术是独立于旧的技术产生出来的。
Go 也不错,虽然没怎么用,但是性能应该是相当可以的。
Ruby、Scala,对于写代码的人来说,这是非常不错的语言。但是如果是团队合作时,就有待商榷。
Hadoop、Spark 来做对应的事。
在数据库出现之前,人们都是使用文件来存储数据的。数据以文件为单位存储在硬盘上,并且这些文件不容易一起管理、修改等等。如下图所示的是我早期存储文件的一种方式:
├── 3.12
│ ├── cover.png
│ └── favicon.ico
└── 3.13
└── template.tex每天我们都会修改、查看大量的不同类型的文件。而由于工作繁忙,我们可能没有办法一一地去分类这些文件。有时选择的便是,优先先按日期把文件一划分,接着再在随后的日子里归档。而这种存储方式大量的依赖于人来索引的工作,在很多时候往往显得不是很靠谱。并且当我们将数据存储进去后,往往很难进行修改。大量的 Log 文件就需要专门的工作来分析和使用,依赖于人来解析这些日志往往显得不是很靠谱。这时我们就需要一些重量级的工具,如用 Logstash、ElasticSearch、Kibana 来处理 Nginx 访问日志。
而对于那些非专业人员来说,使用 Excel 这样的工具往往显得比较方便。他们不需要去操作数据库,也不需要专业的知识来处理这些知识。只是从某种意义上来说,Excel 应该归属于数据库的范畴。
数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解其具体的数据存放方式。
数据库里存储着大量的数据,在我们对系统建模的时候,也在决定系统的基础模型。
MongoDB 这类的数据库,也是存在数据模型,但说的却是嵌入子文档。在业务量大的情况下,数据库在考验公司的技术能力,想想便觉得 Amazon RDS 挺好的。
React Native,虽然这个框架还在有条不紊地挖坑中,但是这真的是太爽了。以后我们只需要一次开发就可以多处运行了,再也没有比这更爽的事情发生了。
HTML5 推出了一种在单个 TCP 连接上进行全双工通讯的协议WebSocket。
HTML5 推出了一种在单个 TCP 连接上进行全双工通讯的协议WebSocket。
WebSocket 可以让客户端和服务器之间存在持久的连接,而且双方都可以随时开始发送数据。
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
虽然基于 Git 的工作流可能并不是一个非常好的实践,但是在这里我们以这个工作流做为实践来开展我们的项目。如下图所示是一个基于 Git 的项目流:
 基于 Git 的工作流
基于 Git 的工作流
我们日常会工作在 “develop” 分支(那条线)上,通常来说每个迭代我们会发布一个新的版本,而这个新的版本将会直接上线到产品环境。那么上线到产品环境的这个版本就需要打一个版本号——这样不仅可以方便跟踪我们的系统,而且当出错的时候我们也可以直接回滚到上一个版本。如果在上线的时候有些 Bug 不得不去修复,并且由于上线的新功能很重要,我们就需要一些 Hotfix。而从整个过程来看,版本控制起了一个非常大的作用。
不仅仅如此,版本控制的最大重要是在开发的过程中扮演的角色。通过版本管理系统,我们可以:
- 将某个文件回溯到之前的状态。
- 将项目回退到过去某个时间点。
- 在修改 Bug 时,可以查看修改历史,查出修改原因
- 只要版本控制系统还在,你可以任意修改项目中的文件,并且还可以轻松恢复。
常用的版本管理系统有 Git、SVN,但是从近年来看 Git 似乎更受市场欢迎。
GitHub 新建免费的公开仓库或在Coding.net 新建免费的私有仓库。
按照 GitHub 的文档 或 Coding.net 的文档 配置 SSH Key,然后将代码仓库 clone 到本地,其实就是将代码复制到你的机器里,并交由 Git 来管理:
$ git clone git@github.com:username/repository.git
或
$ git clone git@git.coding.net:username/repository.git或使用 HTTPS 地址进行 clone:
$ git clone https://username:password@github.com/username/repository.git
或
$ git clone https://username:password@git.coding.net/username/repository.git你可以修改复制到本地的代码了( symfony-docs-chs 项目里都是 rst 格式的文档)。当你觉得完成了一定的工作量,想做个阶段性的提交:
向这个本地的代码仓库添加当前目录的所有改动:
$ git add .或者只是添加某个文件:
$ git add -p我们可以输入
$ git status来看现在的状态,如下图是添加之前的:
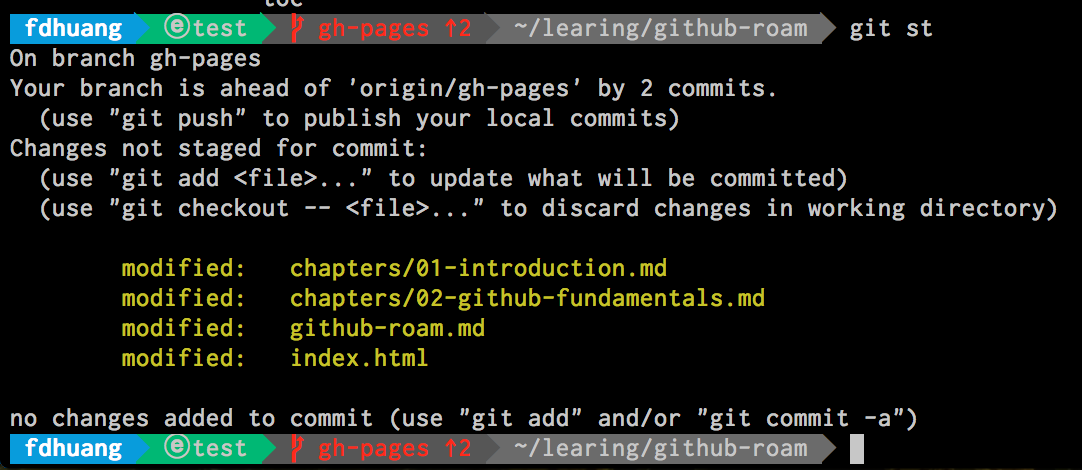 Before add
Before add
下面是添加之后 的
 After add
After add
可以看到状态的变化是从黄色到绿色,即 unstage 到 add。
在完成添加之后,我们就可以写入相应的提交信息——如这次修改添加了什么内容 、这次修改修复了什么问题等等。在我们的工作流程里,我们使用 Jira 这样的工具来管理我们的项目,也会在我们的 Commit Message 里写上作者的名字,如下:
$ git commit -m "[GROWTH-001] Phodal: add first commit & example"在这里的GROWTH-001就相当于是我们的任务号,Phodal 则对应于用户名,后面的提交信息也会写明这个任务是干嘛的。
由于有测试的存在,在完成提交之后,我们就需要运行相应的测试来保证我们没有破坏原来的功能。因此,我们就可以PUSH我们的代码到服务器端:
$ git push这样其他人就可以看到我们修改的代码。
Docker 这一类容器里运行你的程序的话,那么也会先到达 Docker。随后这个请求就会交由 HTTP 服务器来处理,如 Apache、Nginx,这些 HTTP 服务器再将这些请求交由对应的应用或脚本来处理。随后将交由语言底层的指令来处理。
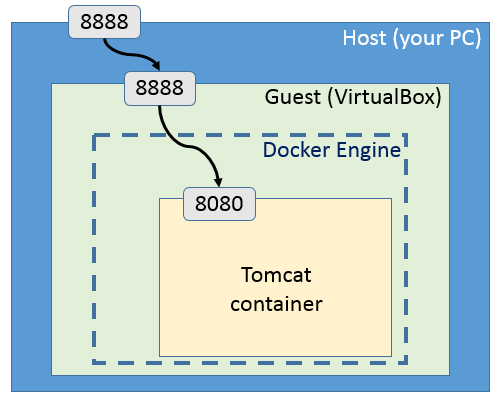 Docker Tomcat
Docker Tomcat
不同的环境有不同的选择,当然也可以结合在一起。不过,从理论上来说在最外层还是应该有一个真机的,但是我想大家都有这个明确的概念,就不多解释了。
Container),内含应用软件本身的代码,以及所需要的操作系统核心和库。通过统一的名字空间和共用 API 来分配不同软件容器的可用硬件资源,创造出应用程序的独立沙箱运行环境,使得 Linux 用户可以容易的创建和管理系统或应用容器。
我们可以将之以上面说到的虚拟机作一个简单的对比,其架构图如下所示:
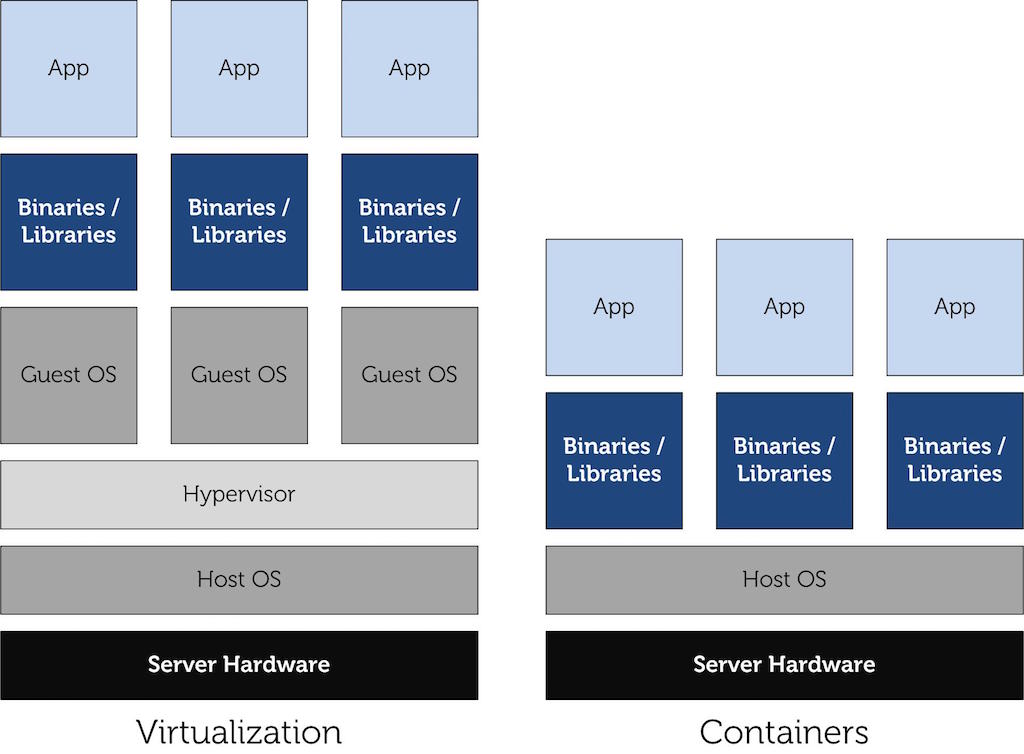 LXC vs VM
LXC vs VM
我们会发现虚拟机中多了一层 Hypervisor——运行在物理服务器和操作系统之间,它可以让多个操作系统和应用共享一套基础物理硬件。这一层级可以协调访问服务器上的所有物理设备和虚拟机,然而由于这一层级的存在,它也将消耗更多的能量。据爱立信研究院和阿尔托大学发表的论文表示:Docker、LXC 与 Xen、KVM 在完成相同的工作时要少消耗10%的能耗。
LXC 主要是利用 cgroups 与 namespace 的功能,来向提供应用软件一个独立的操作系统运行环境。cgroups(即Control Groups)是 Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源的机制。而由 namespace 来责任隔离控制。
与虚拟机相比,LXC 隔离性方面有所不足,这就意味着在实现可移植部署会遇到一些困难。这时候,我们就需要 Docker 来提供一个抽象层,并提供一个管理机制。
Java Web 应用的过程中,我们在开发环境使用 Jetty 来运行我们的服务,而在生产环境使用 Tomcat 来运行。他们都是 Servlet 容器,可以在其上面运行着同一个 Servlet 应用。Servlet 是指由 Java 编写的服务器端程序,它们是为响应 Web 应用程序上下文中的 HTTP 请求而设计的。它是应用服务器中位于组件和平台之间的接口集合。
Tomcat 服务器是一个免费的开放源代码的 Web 应用服务器。它运行时占用的系统资源小,扩展性好,支持负载平衡与邮件服务等开发应用系统常用的功能。除此,它还是一个 Servlet 和 JSP 容器,独立的 Servlet 容器是 Tomcat 的默认模式。其架构如下图所示:
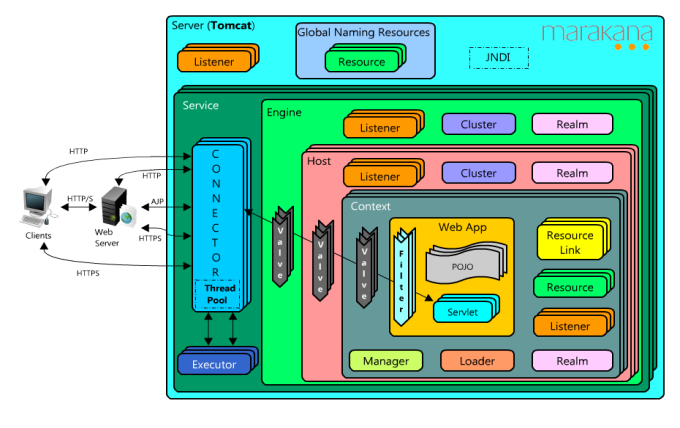 Tomcat架构
Tomcat架构
Servlet 被部署在应用服务器中,并由容器来控制其生命周期。在运行时由 Web 服务器软件处理一般请求,并把 Servlet 调用传递给“容器”来处理。并且 Tomcat 也会负责对一些静态资源的处理。
MySQL,如下图是所示的是 MySQL 的架构图:
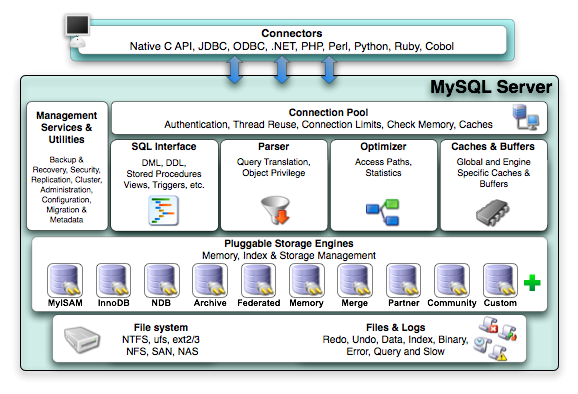 MySQL
MySQL
MySQL 在最顶层提供了一个名为 SQL 的查询语言,这个查询语言只能用于查询数据库,然而它却是一种更高级的用法。它不像通用目的语言那样目标范围涵盖一切软件问题,而是专门针对某一特定问题的计算机语言,即领域特定语言。
Html5 使用 ApplicationCache 接口可以解决由离线带来的部分难题。前提是你需要访问的 Web 页面至少被在线访问过一次。
如何去管理你的 Idea》中说的一样:
我们经常说的是我们缺少一个 Idea。过去我也一直觉得我缺少一些 Idea,今天发现并非如此,我们只是缺少记录的手段。
我们经常说的是我们缺少一个 Idea。过去我也一直觉得我缺少一些 Idea,今天发现并非如此,我们只是缺少记录的手段。
我们并不缺少 Idea,我们只是一直没有去记录。随着时间的增长,我发现我的 GitHub 上的 Idea 墙(ideas)一直在不断地增加。以至于,我有一个新的 Idea 就是整理这个 Idea 墙。
而作为一个程序员,我们本身就可以具备构建一个系统的能力,只是对于大多数人来说需要多加的练习。有意思的一点是,这里的构建系统与一般的构建系统有一点不太一样的是,我们需要快速地构建出一个 MVP 产品。MVP 简单地来说,就是最小可用的产品。如下图的右边所示:
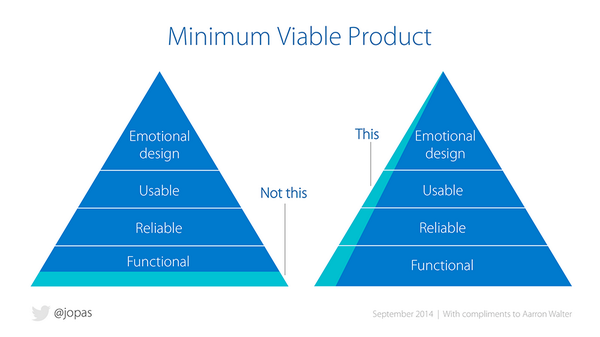 MVP
MVP
在每一层级上都实现一定的功能,使得这个系统可用,而非构建一个非常完整的系统。随后,我们就可以寻找一些种子用户来改进我们的产品。
算法来对其进行分析。
一般来说,我们都利用现有的工具来完成大部分的工作。要使用哪一类工具,取决于我们如要分析的数据的数量级了。如果只是一般的数量级,我们可以考虑用 R 语言、Python、Octave 等单机工具来完成。如果是大量的数据,那么我们就需要考虑用 Hadoop、Spark 来完成这个级别的工作。
而一般来说,这个过程可能是要经过一系列的工具才能完成。如在之前我在分析我的博客的日志时(1G左右),我用 Hadoop + Apache Pig + Jython 来将日志中的 IP 转换为 GEO 信息,再将 GEO 信息存储到 ElasticSearch 中。随后,我们就可以用 AMap、leaflet 这一类 GEO 库将这些点放置到地图上。
PageSpeed。它主要的功能是针对前端页面而进行服务器端的优化,对前端设计人员来说,可以省去优化 css、js 以及图片的过程。它可以对 CSS 和 JavaScript 压缩、合并、级联、内联,生成一个新的 Script 和 CSS 文件 。还有图像优化:剥离元数据、动态调整,重新压缩,如针对 Chrome 浏览器生成 WebP 文件。还可以推迟图像和 JavaScript 加载。
用户体验与网站内容
不可忽略的一些因素是内容才是最优质的部分,没有内容一切 SEO 都是无意义的。
Google Fresh Factor
网站速度分析与 traceroute
Nginx ngx_pagespeed nginx 前端优化模块编译
机器人抓取最新的页面并处理和更新与新内容对应的索引的时间因素。
而这可能是相当长一段时间,尤其是当你正在处理 PB 级的内容时。
而这可能是相当长一段时间,尤其是当你正在处理 PB 级的内容时。
SEO 是一个长期的过程,很少有网站可以在短期内有一个很好的位置,除非是一个热门的网站,然而在它被发现之前也会一个过程。
Defining UX,这又是一篇不是翻译的翻译。
1:
- 持续集成中的任何一个环节都是自动完成的,无需太多的人工干预,有利于减少重复过程以节省时间、费用和工作量;
- 持续集成保障了每个时间点上团队成员提交的代码是能成功集成的。换言之,任何时间点都能第一时间发现软件的集成问题,使任意时间发布可部署的软件成为了可能;
- 持续集成还能利于软件本身的发展趋势,这点在需求不明确或是频繁性变更的情景中尤其重要,持续集成的质量能帮助团队进行有效决策,同时建立团队对开发产品的信心。
2难以发生。
- 持续集成中的任何一个环节都是自动完成的,无需太多的人工干预,有利于减少重复过程以节省时间、费用和工作量;
- 持续集成保障了每个时间点上团队成员提交的代码是能成功集成的。换言之,任何时间点都能第一时间发现软件的集成问题,使任意时间发布可部署的软件成为了可能;
- 持续集成还能利于软件本身的发展趋势,这点在需求不明确或是频繁性变更的情景中尤其重要,持续集成的质量能帮助团队进行有效决策,同时建立团队对开发产品的信心。
2难以发生。
在敏捷团队里,Retro 通常会发生一个迭代的结束与下一个迭代的开始之间,这看上去就是我们的除旧迎新。相信很多人都会对自我进行总结,随后改进。而 Retro 便是对团队进行改进,即发生了一些什么不好的事,而这些事可以变好,那么我们就应该对此进行改进。
Retro 是以整个团队为核心去考虑问题的,通常来说没有理由以个人为对象。因为敏捷回顾有一个最高指导原则,即:
无论我们发现了什么,考虑到当时的已知情况、个人的技术水平和能力、可用的资源,以及手上的状况,我们理解并坚信:每个人对自己的工作都已全力以赴。
下面就让我们来看看在一个团队里是如何 Retro 的。
微服务架构中,它提倡将单一应用程序划分成一组小的服务,这些服务之间互相协调、互相配合。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相沟通。每个服务都应该有自己独立的数据库来存储数据。
 分散数据
分散数据
Django 从某种意义上有点接近微服务的概念,只是实际上并没有。因为它没有实现 Play 框架的异步请求机制。抱句话来说,应用很容易就会在调用 JDBC、Streaming API、HTTP 请求等一系列的请求中发生阻塞。
这些服务都是独立的,对于服务的请求也是独立的。使用微服务来构建的应用,不会因为一个服务的瘫痪让整个系统瘫痪。最后,这一个个的微服务将合并成这个系统。
 Combined List
Combined List
我们将我们后台的服务变成微服务的架构,在我们的前台使用 Reactive 编程,这样我们就可以结合两者的优势,解耦出更好的架构模式。然而,这其中还有一个让人不爽的问题,即数据库。如果我们使用多个数据库,那么维护成本也随着上升。而如果我们可以在后台使用类似于微服务的 Django MTV 架构,并且它可以支持异步请求的话,并在前台使用 Reactive 来编程,是不是就会更爽一点?
基于 Jenkins 快速搭建持续集成环境↩
以一幢有少许破窗的建筑为例,如果那些窗不被修理好,可能将会有破坏者破坏更多的窗户。最终他们甚至会闯入建筑内,如果发现无人居住,也许就在那里定居或者纵火。又或想像一条人行道有些许纸屑,如果无人清理,不久后就会有更多垃圾,最终人们会视为理所当然地将垃圾顺手丢弃在地上。因此破窗理论强调着力打击轻微罪行有助减少更严重罪案,应该以零容忍的态度面对罪案。↩









 2366
2366

 暂无认证
暂无认证






















 c学C++正好遇到这个问题报错, 整个人都快懵了
c学C++正好遇到这个问题报错, 整个人都快懵了 到【灌水乐园】发言
到【灌水乐园】发言






